Random Forest Là Gì? Hướng Dẫn Chi Tiết Thuật Toán Cho Người Mới Bắt Đầu
Trong thế giới học máy, việc lựa chọn thuật toán phù hợp đóng vai trò then chốt để giải quyết hiệu quả các bài toán phức tạp. Trong số đó, Random Forest nổi lên như một phương pháp mạnh mẽ, linh hoạt và được ứng dụng rộng rãi trong nhiều lĩnh vực. Bài viết này sẽ đi sâu vào phân tích thuật toán Random Forest, từ khái niệm cơ bản, cách thức hoạt động, ưu nhược điểm cho đến các ứng dụng thực tế.
Khái niệm Random Forest là gì?
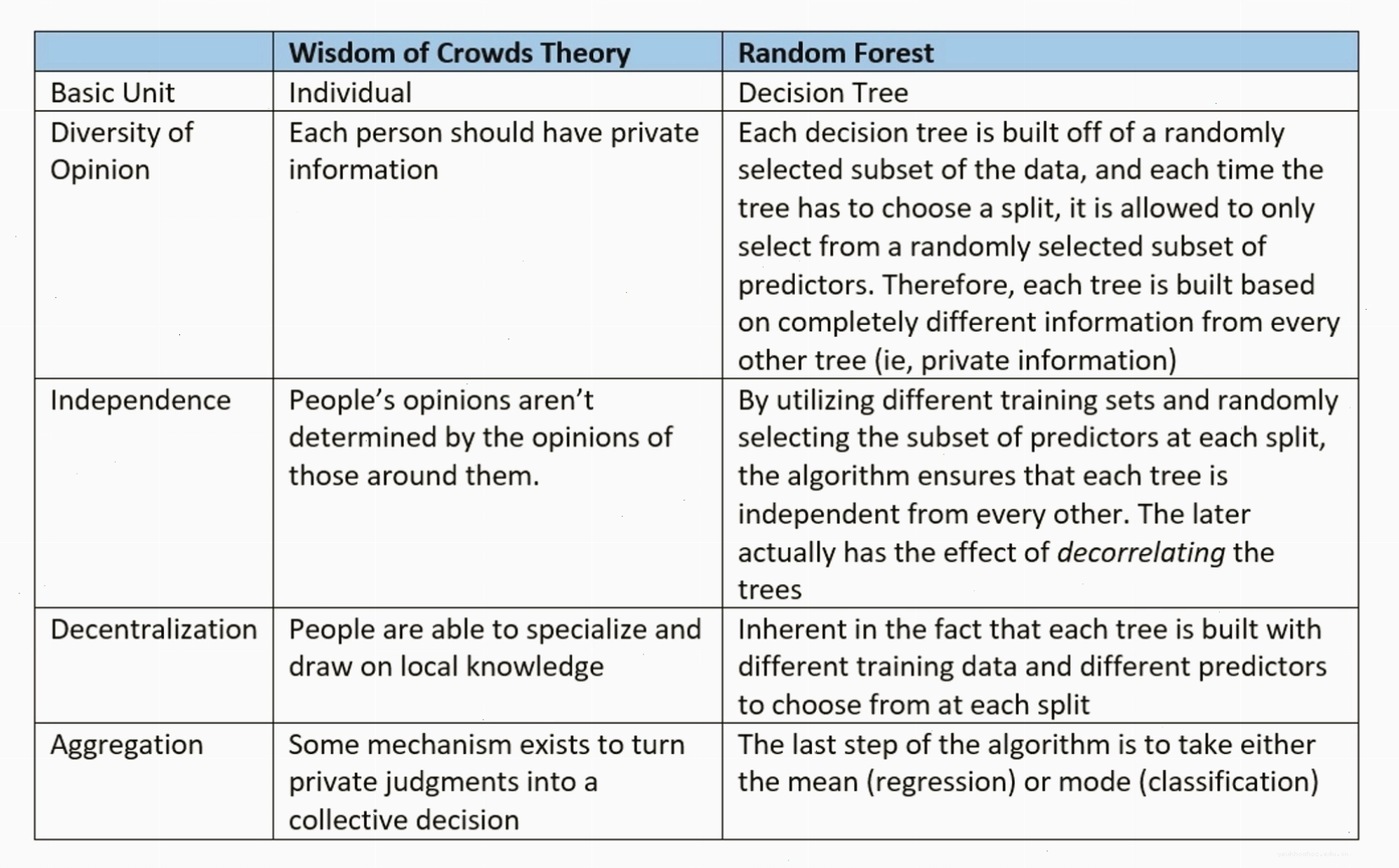
Random Forest, hay còn gọi là Rừng Ngẫu Nhiên, là một kỹ thuật học máy tập hợp (ensemble learning) tiên tiến. Ý tưởng cốt lõi đằng sau Random Forest là việc kết hợp sức mạnh của nhiều cây quyết định độc lập để đưa ra dự đoán cuối cùng. Thay vì dựa vào kết quả của một cây duy nhất, Random Forest tổng hợp kết quả từ tất cả các cây trong rừng để đưa ra quyết định.
Tại sao lại cần Random Forest? Một cây quyết định đơn lẻ thường có xu hướng bị quá khớp (overfitting) với dữ liệu huấn luyện, dẫn đến hiệu suất kém trên dữ liệu mới. Random Forest giải quyết vấn đề này bằng cách:
- Giảm thiểu hiện tượng quá khớp: Bằng cách huấn luyện nhiều cây quyết định trên các tập dữ liệu con khác nhau và sử dụng các đặc trưng con, Random Forest tạo ra một mô hình tổng hợp mạnh mẽ hơn.
- Cải thiện độ chính xác: Sự đa dạng của các cây quyết định giúp mô hình có khả năng khái quát hóa tốt hơn, đưa ra dự đoán chính xác hơn trên dữ liệu chưa từng thấy.
Cơ chế hoạt động của thuật toán Random Forest
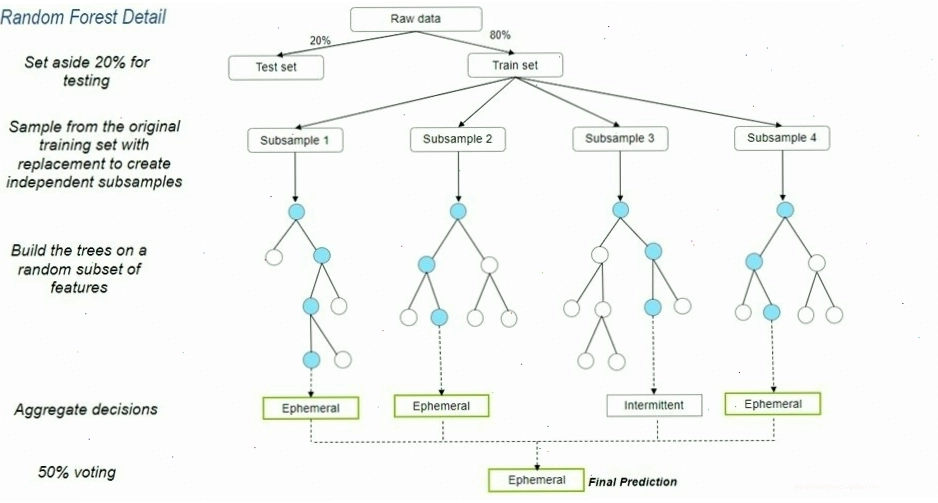
Random Forest hoạt động dựa trên hai nguyên tắc chính: bagging (bootstrap aggregating) và lựa chọn ngẫu nhiên đặc trưng.
1. Bagging (Bootstrap Aggregating)
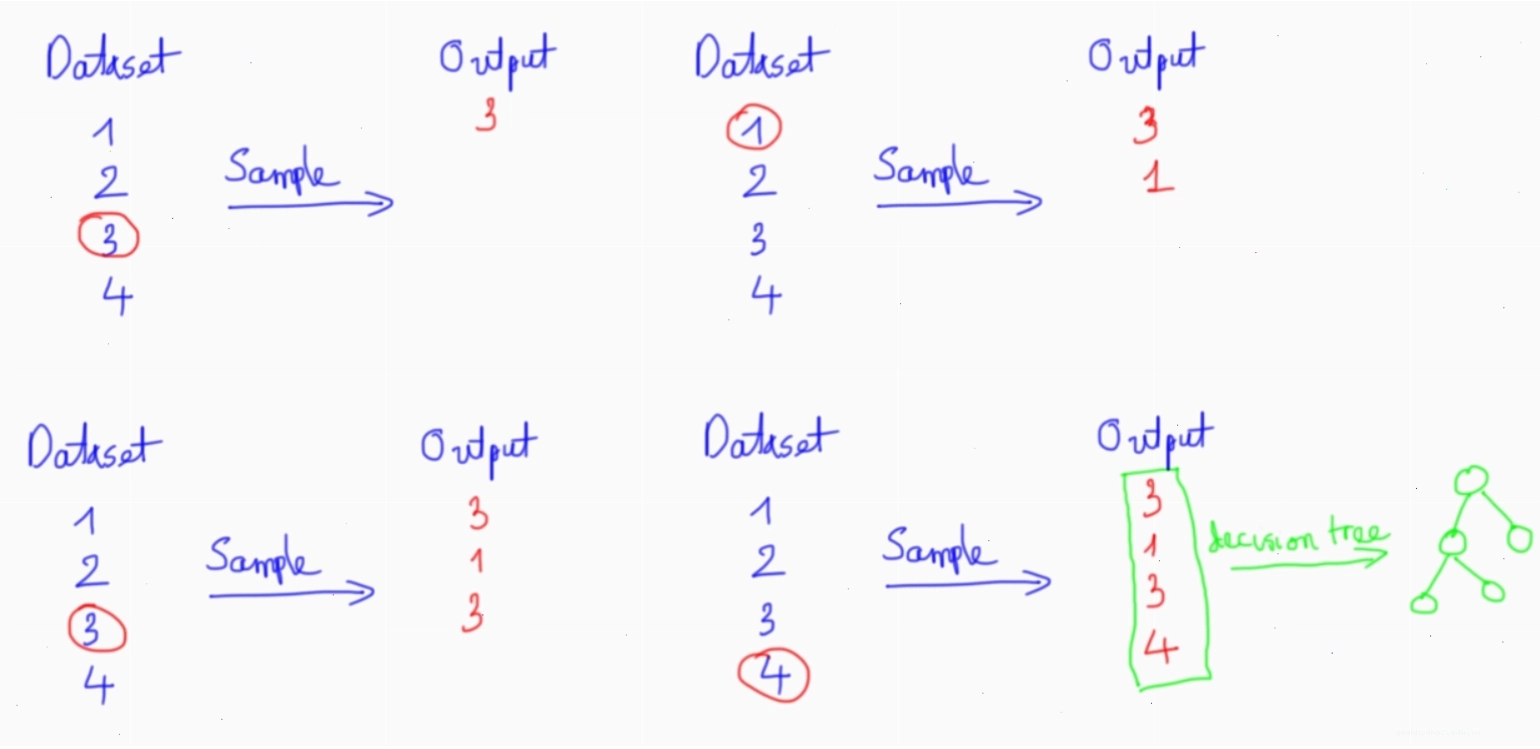
Đây là kỹ thuật lấy mẫu lại (resampling) dữ liệu huấn luyện. Quá trình này diễn ra như sau:
- Tạo các tập dữ liệu con: Từ tập dữ liệu huấn luyện ban đầu, Random Forest sẽ tạo ra nhiều tập con bằng cách lấy mẫu có hoàn lại. Mỗi tập con này sẽ có kích thước xấp xỉ bằng tập dữ liệu gốc, nhưng có thể chứa các mẫu lặp lại và thiếu một số mẫu ban đầu.
- Huấn luyện cây quyết định: Một cây quyết định sẽ được huấn luyện trên mỗi tập con dữ liệu này.
Ví dụ minh họa: Giả sử bạn có 1000 mẫu dữ liệu. Bagging sẽ tạo ra nhiều tập dữ liệu con, mỗi tập 1000 mẫu, có thể có mẫu `X` xuất hiện 2 lần và mẫu `Y` không xuất hiện trong một tập con nhất định.
2. Lựa chọn ngẫu nhiên đặc trưng
Ở mỗi bước chia của cây quyết định, Random Forest không xem xét tất cả các đặc trưng có sẵn mà chỉ chọn ngẫu nhiên một tập con các đặc trưng. Điều này giúp đảm bảo sự đa dạng giữa các cây và ngăn chặn một vài đặc trưng mạnh áp đảo quá trình phân chia.
- Cách thức hoạt động: Tại mỗi nút của cây, thuật toán chọn ra một số lượng đặc trưng nhỏ (ví dụ: căn bậc hai của tổng số đặc trưng) và chỉ tìm ra đặc trưng tốt nhất trong tập con này để thực hiện việc chia.
- Mục đích: Tăng tính độc lập và giảm tương quan giữa các cây, từ đó cải thiện hiệu suất tổng thể của mô hình.
Dự đoán kết quả
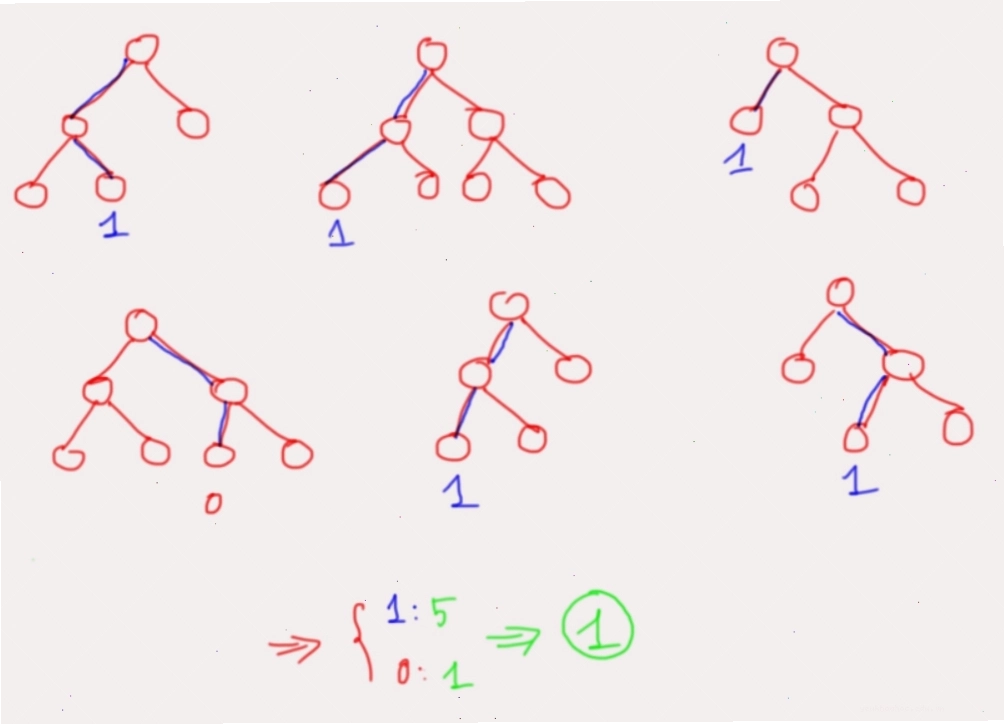
Sau khi các cây quyết định đã được huấn luyện, quá trình dự đoán diễn ra như sau:
- Đối với bài toán phân loại (Random Forest Classifier): Mỗi cây trong rừng sẽ đưa ra một dự đoán. Kết quả cuối cùng được xác định bằng cách bỏ phiếu đa số (majority voting).
- Đối với bài toán hồi quy (Random Forest Regression): Mỗi cây sẽ đưa ra một giá trị dự đoán. Kết quả cuối cùng là trung bình cộng của tất cả các dự đoán từ các cây.
Ưu điểm của Random Forest
Random Forest sở hữu nhiều ưu điểm vượt trội, khiến nó trở thành một lựa chọn hấp dẫn cho nhiều bài toán học máy:
- Độ chính xác cao: Thường cho kết quả tốt hơn so với các thuật toán cây quyết định đơn lẻ hoặc các phương pháp khác như SVM, hồi quy logistic trong nhiều trường hợp.
- Khả năng xử lý dữ liệu lớn: Có thể hoạt động hiệu quả với các tập dữ liệu có số lượng mẫu và số chiều đặc trưng lớn.
- Ít nhạy cảm với nhiễu và ngoại lệ: Nhờ cơ chế lấy mẫu và kết hợp nhiều cây, Random Forest ít bị ảnh hưởng bởi các điểm dữ liệu nhiễu hoặc ngoại lệ.
- Xử lý tốt cả dữ liệu phân loại và số: Có thể áp dụng linh hoạt cho cả hai loại bài toán.
- Đánh giá tầm quan trọng của đặc trưng: Random Forest có thể cung cấp thông tin về mức độ quan trọng của từng đặc trưng đối với việc dự đoán, giúp hiểu rõ hơn về dữ liệu.
- Giảm thiểu quá khớp: Như đã đề cập, đây là một trong những lợi ích cốt lõi của thuật toán.
Nhược điểm của Random Forest
Mặc dù mạnh mẽ, Random Forest cũng có một số hạn chế cần lưu ý:
- Tính toán phức tạp và tốn thời gian: Việc huấn luyện nhiều cây quyết định đòi hỏi tài nguyên tính toán lớn và thời gian lâu hơn so với các thuật toán đơn giản.
- Khó diễn giải: Mặc dù có thể đánh giá tầm quan trọng của đặc trưng, nhưng việc hiểu rõ cách thức một dự đoán cụ thể được đưa ra bởi toàn bộ rừng cây vẫn khó khăn hơn so với một cây quyết định đơn lẻ.
- Tốn bộ nhớ: Cần nhiều bộ nhớ để lưu trữ tất cả các cây quyết định trong rừng.
Ứng dụng của Random Forest
Random Forest được ứng dụng trong rất nhiều lĩnh vực khác nhau nhờ tính linh hoạt và hiệu quả của nó:
- Phân loại ảnh: Sử dụng để phân loại các đối tượng trong ảnh, ví dụ như nhận diện cây trồng, phân loại bệnh thực vật.
- Dự đoán tài chính: Dự đoán biến động thị trường chứng khoán, phát hiện gian lận thẻ tín dụng.
- Y tế: Chẩn đoán bệnh dựa trên các triệu chứng, phân tích dữ liệu gen.
- Bán lẻ: Dự đoán hành vi mua sắm của khách hàng, gợi ý sản phẩm.
- Hệ thống gợi ý: Xây dựng các hệ thống gợi ý cá nhân hóa cho người dùng.
Random Forest Sklearn
Trong Python, thư viện Scikit-learn (sklearn) cung cấp một cách triển khai rất hiệu quả và dễ sử dụng của thuật toán Random Forest. Bạn có thể dễ dàng huấn luyện và sử dụng các mô hình Random Forest Classifier và Random Forest Regression thông qua các lớp tương ứng.
Ví dụ cơ bản với RandomForestClassifier:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification # Tạo dữ liệu giả lập X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=42) # Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Khởi tạo mô hình Random Forest Classifier clf = RandomForestClassifier(n_estimators=100, random_state=42) # Huấn luyện mô hình clf.fit(X_train, y_train) # Dự đoán trên tập kiểm tra y_pred = clf.predict(X_test) # Đánh giá mô hình (ví dụ: độ chính xác) from sklearn.metrics import accuracy_score print(f"Accuracy: {accuracy_score(y_test, y_pred)}") Thư viện sklearn giúp việc triển khai Random Forest trở nên đơn giản, cho phép tùy chỉnh nhiều tham số quan trọng như n_estimators (số lượng cây), max_depth (chiều sâu tối đa của cây), min_samples_split (số mẫu tối thiểu để chia một nút), v.v.
Tóm tắt và Lời khuyên Chuyên gia
Random Forest là một thuật toán học máy đa năng và mạnh mẽ, mang lại hiệu suất cao trong cả bài toán phân loại và hồi quy. Cơ chế hoạt động dựa trên việc kết hợp nhiều cây quyết định độc lập giúp nó khắc phục nhược điểm quá khớp và đạt được độ chính xác ấn tượng. Mặc dù có thể tốn kém về mặt tính toán và khó diễn giải hơn so với các mô hình đơn giản, những lợi ích mà Random Forest mang lại thường vượt trội hơn hẳn.
Lời khuyên: Khi làm việc với dữ liệu dạng bảng, đặc biệt là các bài toán phân loại hoặc hồi quy phức tạp, hãy xem xét Random Forest như một phương pháp đầu tay. Hãy thử nghiệm với các tham số khác nhau để tối ưu hóa hiệu suất cho bài toán cụ thể của bạn. Nếu bạn cần một mô hình dễ diễn giải hơn, có thể cân nhắc các thuật toán khác hoặc sử dụng các kỹ thuật giải thích mô hình cho Random Forest.
Sẵn sàng chinh phục thế giới học máy? Hãy bắt đầu với Random Forest và khám phá sức mạnh của nó ngay hôm nay!